Chapter 10 Intermediate R: Functions, Loops, and Iterative Programming
10.1 Functions
A function is a command that performs a specified operation and returns an output in accordance with that operation. You can literally make a function to do anything you want.
General structure of a basic function:
# example structure
Function_name=function(argument){
Expressions
return(output)
}- Argument is your input. It is the thing you want to perform the operation on.
- Expressions is the actual operation (or operations) you want to perform on the supplied argument
- return tells R to return the result of the Expression to you when done.
This example function takes an input of numbers in the form of a vector and subtracts two from each.
numbers=c(2,10,12,80)
sub_2=function(x){
result= x - 2
return(result)
}
sub_2(numbers)## [1] 0 8 10 78We can also supply the function with a single number and it still works…
sub_2(100)## [1] 98Well this looks useful. So what’s the bigger picture?
One of the primary advantages of functions are that they can reduce a long and complex process, or a process that involves many steps, into a single line of code; thus, creating your own functions is a fast way to make your life easier down the line either at some point in the far future or even in just a few minutes, if you know you will be writing the code for some process two or more times.
Take this script for instance. You can see from the circled parts that I needed to transform three different data sets in a similar way:
knitr::include_graphics(here::here("pics", "repeat_process.jpg"))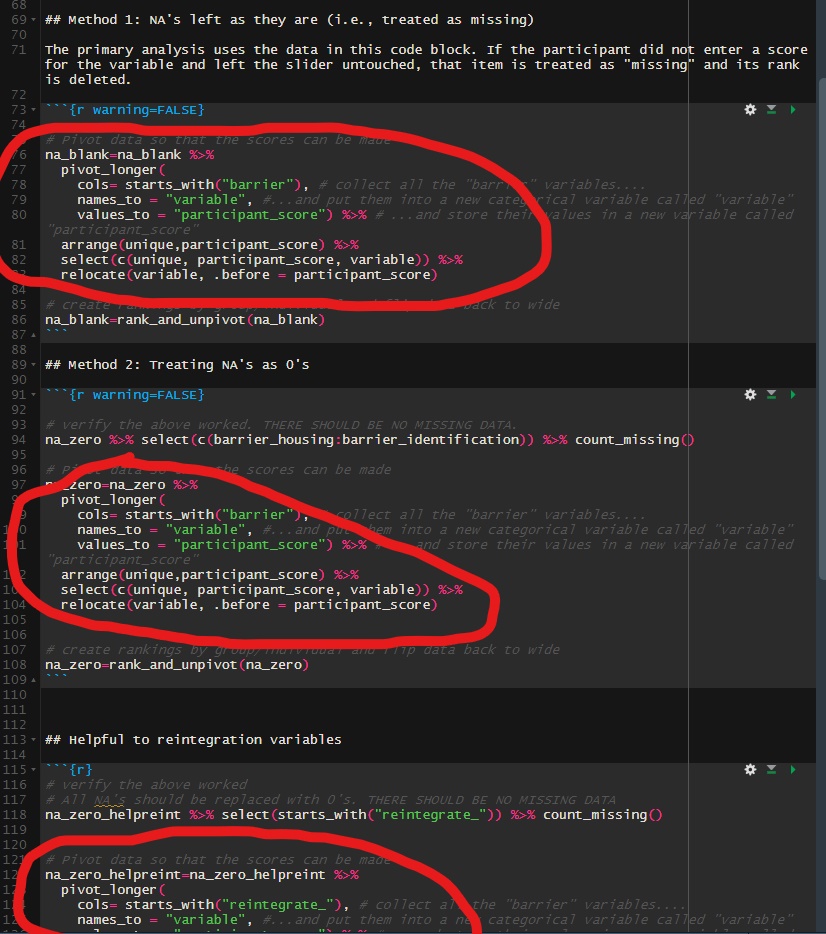
Yes, I could have just done a copy-paste of the original code and tweak it slightly each time…. But that is time consuming, produces a sloppier and longer script, and introduces a lot more room for error because of the repeated code and extra steps.
Better to write a single function that could be applied to all three….
In short, use functions to reduce a multi-step process or a process that you’re implementing >=2 times in a single script into one command. This saves you space and makes the script shorter; it saves you the trouble and effort of re-writing or adapting code from earlier sections; and importantly, reduces the chances of you making a coding error by proxy of the former two.
As a quick example, I was able to replace each of the circled paragraphs of code above with a custom function that ran everything in one simple line. Now instead of 3 whole (and redundant) paragraphs, I now have 3 short lines, like so….
na_zero_helpreint=rotate_data(data = na_zero_helpreint,
variable_prefix = "reintegrate_")
na_blank=rotate_data(data = na_zero_helpreint, variable_prefix = "barrier_")
na_zero=rotate_data(data = na_zero_helpreint, variable_prefix = "barrier_")Limitations to your average, everyday functions. While reducing a whole process or sequence of commands is extremely useful, it still leaves a limitation. For instance, while we avoided copying and pasting whole paragraphs or processes, I still had to copy-paste the same function three times. This still leaves chances for error on the table, and it still leaves us with wasted lines that make the script longer.
In general, when you want to perform some function or process multiple times on multiple items (as above where the same command is used three times on three different data frames), you need to use a for-loop or iterating function. These can reduce further unwanted redundancies by applying the function or process iteratively. Read on for more info.
10.2 For-loops
A for loop is essentially a function that applies a function or given set of operations to multiple things at once, and returns an output of many items.
For example, this code finds the means of every vector/column in a dataset by repeatedly applying the same code over and over to element “i” in the given list:
df <- tibble(
a = rnorm(10),
b = rnorm(10),
c = rnorm(10),
d = rnorm(10)
)
output <- vector("double", ncol(df)) # 1.Output. Create the object you want the results of the loop stored in.
for (i in seq_along(df)) { # 2.Sequence of operations. "For each item 'i' along data frame…"
output[[i]] <- median(df[[i]]) # 3.Body:"every individual item in 'output' = the median of each col in df
}
output## [1] 0.3771802 -0.5176346 0.4171879 0.5704655Check out this book chapter for a great and detailed explanation of for-loops and functional coding.
Although for loops are nice, they are unwieldy. R programmers typically use iterating functions instead. Examples of iterating functions are the lapply, vapply, sapply, etc. family of base R commands. But these can also be confusing and the commands are not great.
The purrr package offers a better way to do iterating functions over base R; it’s the tidyverse way to make efficient and understandable for loops! If you have a need for a for-loop for something, see the next section instead on how to use purrr to make an iterative function. Important to understand conceptually what a for-loop is, but using them is impractical when you have purrr
10.3 purrr and Iterative Functions
All notes here come from Charlotte Wickham’s lecture tutorial below
- Part 1: https://www.youtube.com/watch?v=7UlWJWfZO9M
- Part 2: https://www.youtube.com/watch?v=b0ozKTUho0A&t=1210s
purrr’s map() series of functions offer a way to apply any existing function (even functions you’ve made) to multiple things at once, be it lists, data frame columns, individual items in vector, etc. In short, they are for doing the same type of task repeatedly in a very quick and efficient manner. They work in much the same way as for-loops, but are far simpler to write, and can be applied in the same way to solve the same problems.
How to use purrr
The structure of map() commands is the same as the others in the tidyverse:
#option 1
map(data, function)
# option 2
data %>% map(function)As a quick example and to highlight why purrr is so much more efficient and easier to use than for-loops, look at the same example from before, now using map() instead of a for:
df |> map_dbl(median)## a b c d
## 0.3771802 -0.5176346 0.4171879 0.5704655A single line is all it took to get the same results! And, it follows tidyverse grammar structure.
Now lets get into how it works….
map() commands work like this: For each element of x, do f.
So if you pass it object x and object x is…. - A vector, it will perform function f on every item in the vector - A data frame, it will perform function f on every column in the data frame - A list, it will perform function f on every level in the list
Etc., etc.; the point is it applies a function repeatedly to every element in the object you supply it with.
So lets walk through a case example.
10.3.1 Reproducible example: Scraping web data
This is an example walk through showing how we can use purrr to speed things up dramatically and/or reduce the use of unwanted, extra code in our scripts. In this guide I’ll be building a table of LPGA Tour statistics from multiple webpages.
The workflow for purrr goes like this:
First, you want to figure out how to do each step of your process line-by-line, for a single item. The idea is to try and walk through each step of the process and see exactly what will need to be done each each step and what the code will like, before trying to code it all at once at a higher level.
Once you have each step for the first item figured out, then you make functions for each step that condense that code down to one command.
Lastly, apply each function from your individual steps to all items in your list by using purr::map().
Do for One
library(rvest)
# STEP 1
# Figure out a line-by-line process for one item/one single web page
html1=read_html("https://scores.nbcsports.com/golf/averages.asp?tour=LPGA&rank=04") |>
html_nodes("table.shsTable.shsBorderTable") |>
html_table(fill = TRUE, header=TRUE) |>
as.data.frame() |>
janitor::clean_names()
head(html1)## rank name distance
## 1 1 Maria Fassi 279.255
## 2 2 Bianca Pagdanganan 277.052
## 3 3 Yuka Saso 275.614
## 4 4 Brooke Matthews 275.279
## 5 5 A Lim Kim 274.741
## 6 6 Emily Pedersen 274.669# STEP 2
# create a custom function of the above to shorten and generalize the process
quick_read_html=function(url){
web_page=read_html(url) |>
html_nodes("table.shsTable.shsBorderTable") |> # fortunately this node works for all four pages so it can be baked into the function
html_table(fill = TRUE, header = TRUE) |>
as.data.frame() |>
janitor::clean_names()
return(web_page)
}
# test to verify it works
test=quick_read_html(url= "https://scores.nbcsports.com/golf/averages.asp?tour=LPGA&rank=08")
head(test) # nice ## rank name putt_average
## 1 1 Lydia Ko 1.722
## 2 2 Hyo Joo Kim 1.735
## 3 3 Danielle Kang 1.738
## 4 4 Nasa Hataoka 1.745
## 5 5 Madelene Sagstrom 1.748
## 6 6 Georgia Hall 1.751DO FOR ALL. Now create the object that contains all the elements you want to iterate over, and then pass it to your generalized function with map.
# Step 3a
# create an object that contains ALL elements of interest
URLs=c("https://scores.nbcsports.com/golf/averages.asp?tour=LPGA&rank=04",
"https://scores.nbcsports.com/golf/averages.asp?tour=LPGA&rank=08",
"https://scores.nbcsports.com/golf/averages.asp?tour=LPGA&rank=06",
"https://scores.nbcsports.com/golf/averages.asp?tour=LPGA&rank=12")
# Step 4
# use the power of map and be amazed
lpga_data= URLs |> map(quick_read_html)
head(lpga_data)## [[1]]
## rank name distance
## 1 1 Maria Fassi 279.255
## 2 2 Bianca Pagdanganan 277.052
## 3 3 Yuka Saso 275.614
## 4 4 Brooke Matthews 275.279
## 5 5 A Lim Kim 274.741
## 6 6 Emily Pedersen 274.669
## 7 7 Madelene Sagstrom 273.399
## 8 8 Lexi Thompson 272.842
## 9 9 Maude-Aimee Leblanc 272.377
## 10 10 Nelly Korda 272.280
## 11 11 Nanna Koerstz Madsen 271.985
## 12 12 Jessica Korda 271.827
## 13 13 Pauline Roussin-Bouchard 271.775
## 14 14 Rachel Rohanna 270.774
## 15 15 Patty Tavatanakit 269.945
## 16 16 Carlota Ciganda 269.691
## 17 17 Alana Uriell 269.509
## 18 18 Atthaya Thitikul 269.005
## 19 19 Weiwei Zhang 268.636
## 20 20 Janie Jackson 268.045
## 21 21 Minjee Lee 267.715
## 22 22 Amanda Doherty 267.700
## 23 23 Cydney Clanton 267.360
## 24 24 Yu Liu 267.199
## 25 25 Angel Yin 267.148
## 26 26 Brooke Henderson 267.079
## 27 27 Perrine Delacour 266.850
## 28 28 Charley Hull 266.445
## 29 29 Jennifer Kupcho 266.273
## 30 30 Alena Sharp 265.935
## 31 31 Georgia Hall 265.679
## 32 32 Ally Ewing 265.455
## 33 33 Sei Young Kim 265.424
## 34 34 Nasa Hataoka 265.242
## 35 35 Albane Valenzuela 265.212
## 36 36 Yealimi Noh 264.686
## 37 37 Gaby Lopez 264.419
## 38 38 Lilia Vu 264.006
## 39 39 Frida Kinhult 263.857
## 40 40 Hyejin Choi 263.734
## 41 41 Ryann O'Toole 263.613
## 42 42 Hannah Green 263.506
## 43 43 Celine Herbin 263.327
## 44 44 Ruixin Liu 263.017
## 45 45 Stephanie Meadow 263.007
## 46 46 Daniela Darquea 263.000
## 47 47 Katherine Perry-Hamski 262.543
## 48 48 Sung Hyun Park 262.396
## 49 49 Alison Lee 262.273
## 50 50 Xiyu Lin 262.250
## 51 51 Savannah Vilaubi 261.867
## 52 52 Dewi Weber 261.824
## 53 53 Pajaree Anannarukarn 261.638
## 54 54 Peiyun Chien 261.546
## 55 55 Gerina Mendoza 261.511
## 56 56 Fatima Fernandez Cano 261.406
## 57 57 Haylee Harford 261.155
## 58 58 Amy Yang 261.154
## 59 59 Sarah Schmelzel 260.633
## 60 60 Amy Olson 259.643
## 61 61 Jodi Ewart Shadoff 258.975
## 62 62 Lauren Hartlage 258.975
## 63 63 Lindy Duncan 258.962
## 64 64 Lauren Coughlin 258.862
## 65 65 Brittany Lincicome 258.719
## 66 66 Ariya Jutanugarn 258.675
## 67 67 Mel Reid 258.521
## 68 68 Giulia Molinaro 258.509
## 69 69 Katherine Kirk 258.489
## 70 70 Jaye Marie Green 258.417
## 71 71 Sophia Schubert 258.403
## 72 72 Ruoning Yin 258.279
## 73 73 Eun-Hee Ji 258.129
## 74 74 Annie Park 258.117
## 75 75 Stephanie Kyriacou 258.115
## 76 76 Min Lee 257.983
## 77 77 Lauren Stephenson 257.947
## 78 78 Jeong Eun Lee 257.747
## 79 79 Hinako Shibuno 257.648
## 80 80 Gina Kim 257.613
## 81 81 Elizabeth Nagel 257.520
## 82 82 Mi Hyang Lee 257.506
## 83 83 Matilda Castren 257.467
## 84 84 Isi Gabsa 257.085
## 85 85 Paula Reto 256.840
## 86 86 Sophia Popov 256.762
## 87 87 Sanna Nuutinen 256.574
## 88 88 Elizabeth Szokol 255.967
## 89 89 Brittany Lang 255.885
## 90 90 Angela Stanford 255.857
## 91 91 Megan Khang 255.679
## 92 92 Karis Davidson 255.359
## 93 93 Lydia Ko 255.343
## 94 94 Hyo Joo Kim 255.325
## 95 95 Casey Danielson 255.064
## 96 96 Ana Belac 255.020
## 97 97 Tiffany Chan 254.689
## 98 98 Agathe Laisne 254.659
## 99 99 Jenny Shin 254.644
## 100 100 Robynn Ree 254.513
## 101 102 Pernilla Lindberg 254.091
## 102 103 Esther Henseleit 254.080
## 103 104 Celine Boutier 254.000
## 104 105 Na Rin An 253.696
## 105 106 Jenny Coleman 253.656
## 106 107 Yu-Sang Hou 253.643
## 107 108 Jennifer Song 253.579
## 108 109 Linnea Johansson 253.509
## 109 110 Jennifer Chang 253.375
## 110 111 Wei-Ling Hsu 253.229
## 111 112 Allisen Corpuz 252.925
## 112 113 Pornanong Phatlum 252.874
## 113 114 Wichanee Meechai 252.580
## 114 115 Kelly Tan 252.446
## 115 116 Kaitlyn Papp 252.365
## 116 117 Sarah Kemp 252.222
## 117 118 Morgane Metraux 252.139
## 118 119 Ashleigh Buhai 251.692
## 119 120 Muni He 251.633
## 120 121 Danielle Kang 251.172
## 121 122 Bronte Law 250.623
## 122 123 Moriya Jutanugarn 250.589
## 123 124 Leona Maguire 250.306
## 124 125 Marina Alex 250.259
## 125 126 Lauren Kim 250.139
## 126 127 Gemma Dryburgh 249.841
## 127 128 Sarah Jane Smith 249.389
## 128 129 Jin Young Ko 249.282
## 129 130 In Gee Chun 249.077
## 130 131 Cristie Kerr 248.966
## 131 132 So Yeon Ryu 248.712
## 132 133 Ayaka Furue 248.645
## 133 134 Christina Kim 248.489
## 134 135 Maddie Szeryk 248.324
## 135 136 Allison Emrey 247.010
## 136 137 Su-Hyun Oh 246.942
## 137 138 Jasmine Suwannapura 246.813
## 138 139 Emma Talley 246.571
## 139 140 Caroline Masson 246.448
## 140 141 Mariah Stackhouse 246.425
## 141 142 Anna Nordqvist 246.409
## 142 143 Chella Choi 246.323
## 143 144 Mirim Lee 246.269
## 144 145 Mina Harigae 245.803
## 145 146 Brittany Altomare 245.701
## 146 147 Cheyenne Knight 245.276
## 147 148 Caroline Inglis 245.109
## 148 149 Haeji Kang 245.081
## 149 150 Na Yeon Choi 243.988
## 150 151 Brianna Do 243.839
## 151 152 Lindsey Weaver 243.211
## 152 153 Inbee Park 242.287
## 153 154 In-Kyung Kim 242.244
## 154 155 Stacy Lewis 241.671
## 155 156 Andrea Lee 241.328
## 156 157 Marissa Steen 240.720
## 157 158 Lizette Salas 240.642
## 158 159 Charlotte Thomas 238.644
## 159 160 Vivian Hou 238.543
## 160 161 Yae Eun Hong 238.306
## 161 162 Dana Finkelstein 235.241
## 162 163 Aditi Ashok 235.105
##
## [[2]]
## rank name putt_average
## 1 1 Lydia Ko 1.722
## 2 2 Hyo Joo Kim 1.735
## 3 3 Danielle Kang 1.738
## 4 4 Nasa Hataoka 1.745
## 5 5 Madelene Sagstrom 1.748
## 6 6 Georgia Hall 1.751
## 7 7 Yuka Saso 1.752
## 8 8 Celine Boutier 1.753
## 9 9 Lilia Vu 1.757
## 10 10 Xiyu Lin 1.759
## 11 11 Leona Maguire 1.759
## 12 12 Andrea Lee 1.760
## 13 13 Stephanie Kyriacou 1.761
## 14 14 Jeong Eun Lee 1.761
## 15 15 Karis Davidson 1.764
## 16 16 Carlota Ciganda 1.765
## 17 17 Nelly Korda 1.766
## 18 18 Amanda Doherty 1.766
## 19 19 Brooke Henderson 1.767
## 20 20 Hannah Green 1.768
## 21 21 Jessica Korda 1.770
## 22 22 Atthaya Thitikul 1.771
## 23 23 Ruoning Yin 1.772
## 24 24 Amy Yang 1.772
## 25 25 Hyejin Choi 1.775
## 26 26 Charley Hull 1.777
## 27 27 Ayaka Furue 1.778
## 28 28 Gaby Lopez 1.780
## 29 29 Patty Tavatanakit 1.781
## 30 30 Cheyenne Knight 1.783
## 31 31 Su-Hyun Oh 1.784
## 32 32 Kaitlyn Papp 1.785
## 33 33 Minjee Lee 1.786
## 34 34 Jin Young Ko 1.787
## 35 35 Sarah Jane Smith 1.787
## 36 36 Sei Young Kim 1.788
## 37 37 Megan Khang 1.788
## 38 38 Angel Yin 1.789
## 39 39 Chella Choi 1.789
## 40 40 Frida Kinhult 1.790
## 41 41 Eun-Hee Ji 1.791
## 42 42 Yae Eun Hong 1.793
## 43 43 Paula Reto 1.793
## 44 44 Ryann O'Toole 1.793
## 45 45 Pauline Roussin-Bouchard 1.793
## 46 46 A Lim Kim 1.794
## 47 47 Nanna Koerstz Madsen 1.794
## 48 48 Cristie Kerr 1.795
## 49 49 Gemma Dryburgh 1.795
## 50 50 Lexi Thompson 1.795
## 51 51 Na Rin An 1.796
## 52 52 Inbee Park 1.797
## 53 53 Alison Lee 1.798
## 54 54 Yu Liu 1.798
## 55 55 Lauren Stephenson 1.799
## 56 56 Isi Gabsa 1.799
## 57 57 So Yeon Ryu 1.800
## 58 58 Alena Sharp 1.801
## 59 59 Mina Harigae 1.801
## 60 60 In Gee Chun 1.801
## 61 61 Morgane Metraux 1.802
## 62 62 Allisen Corpuz 1.802
## 63 63 Jasmine Suwannapura 1.803
## 64 64 Haeji Kang 1.804
## 65 65 Ashleigh Buhai 1.804
## 66 66 Pajaree Anannarukarn 1.804
## 67 67 Perrine Delacour 1.805
## 68 68 Maude-Aimee Leblanc 1.805
## 69 69 Sarah Schmelzel 1.806
## 70 70 Brittany Altomare 1.807
## 71 71 Aditi Ashok 1.808
## 72 72 Lizette Salas 1.808
## 73 73 Jennifer Chang 1.808
## 74 74 Caroline Inglis 1.808
## 75 75 Moriya Jutanugarn 1.808
## 76 76 Jenny Shin 1.809
## 77 77 Ariya Jutanugarn 1.809
## 78 78 Stacy Lewis 1.810
## 79 79 Kelly Tan 1.811
## 80 80 Marina Alex 1.812
## 81 81 Weiwei Zhang 1.813
## 82 82 Jennifer Kupcho 1.813
## 83 83 Emma Talley 1.814
## 84 84 Elizabeth Szokol 1.814
## 85 85 Linnea Johansson 1.814
## 86 86 Allison Emrey 1.814
## 87 87 Sung Hyun Park 1.814
## 88 88 Esther Henseleit 1.815
## 89 89 Hinako Shibuno 1.816
## 90 90 Tiffany Chan 1.816
## 91 91 Jodi Ewart Shadoff 1.816
## 92 92 Katherine Kirk 1.818
## 93 93 Pernilla Lindberg 1.818
## 94 94 Alana Uriell 1.819
## 95 95 Lindsey Weaver 1.819
## 96 96 Katherine Perry-Hamski 1.822
## 97 97 Caroline Masson 1.823
## 98 98 Albane Valenzuela 1.823
## 99 99 Mi Hyang Lee 1.823
## 100 100 Janie Jackson 1.824
## 101 101 Sophia Popov 1.824
## 102 102 Wichanee Meechai 1.824
## 103 103 Stephanie Meadow 1.825
## 104 104 Min Lee 1.827
## 105 105 Matilda Castren 1.827
## 106 106 Sanna Nuutinen 1.827
## 107 107 Annie Park 1.827
## 108 108 Ruixin Liu 1.828
## 109 109 Yu-Sang Hou 1.832
## 110 110 Maria Fassi 1.834
## 111 111 Pornanong Phatlum 1.835
## 112 112 Amy Olson 1.836
## 113 113 Anna Nordqvist 1.836
## 114 114 Lindy Duncan 1.837
## 115 115 Charlotte Thomas 1.837
## 116 116 Wei-Ling Hsu 1.838
## 117 117 Maddie Szeryk 1.838
## 118 118 Sarah Kemp 1.838
## 119 119 In-Kyung Kim 1.838
## 120 120 Angela Stanford 1.839
## 121 121 Sophia Schubert 1.839
## 122 122 Daniela Darquea 1.839
## 123 123 Gina Kim 1.839
## 124 124 Yealimi Noh 1.840
## 125 125 Ana Belac 1.840
## 126 126 Gerina Mendoza 1.840
## 127 127 Cydney Clanton 1.841
## 128 128 Rachel Rohanna 1.841
## 129 129 Brianna Do 1.841
## 130 130 Celine Herbin 1.841
## 131 131 Brittany Lang 1.842
## 132 132 Christina Kim 1.843
## 133 133 Dana Finkelstein 1.844
## 134 134 Elizabeth Nagel 1.844
## 135 135 Bianca Pagdanganan 1.844
## 136 136 Emily Pedersen 1.845
## 137 137 Lauren Coughlin 1.846
## 138 138 Muni He 1.847
## 139 140 Na Yeon Choi 1.848
## 140 141 Agathe Laisne 1.850
## 141 142 Brittany Lincicome 1.851
## 142 143 Jennifer Song 1.853
## 143 144 Ally Ewing 1.854
## 144 145 Giulia Molinaro 1.854
## 145 146 Peiyun Chien 1.857
## 146 147 Dewi Weber 1.858
## 147 148 Bronte Law 1.859
## 148 149 Jaye Marie Green 1.860
## 149 150 Lauren Hartlage 1.861
## 150 151 Haylee Harford 1.862
## 151 152 Robynn Ree 1.867
## 152 153 Mariah Stackhouse 1.868
## 153 154 Brooke Matthews 1.868
## 154 155 Fatima Fernandez Cano 1.869
## 155 156 Jenny Coleman 1.870
## 156 157 Lauren Kim 1.874
## 157 158 Savannah Vilaubi 1.884
## 158 159 Mirim Lee 1.886
## 159 160 Casey Danielson 1.897
## 160 161 Vivian Hou 1.900
## 161 162 Mel Reid 1.901
## 162 163 Marissa Steen 1.916
##
## [[3]]
## rank name greens_hit
## 1 1 Ally Ewing 77.7
## 2 2 Lexi Thompson 77.2
## 3 3 Jodi Ewart Shadoff 76.5
## 4 4 Hyejin Choi 76.5
## 5 5 Brooke Henderson 76.3
## 6 6 Minjee Lee 76.2
## 7 7 Xiyu Lin 75.9
## 8 8 Megan Khang 75.4
## 9 9 Nelly Korda 75.4
## 10 10 Atthaya Thitikul 74.9
## 11 11 Anna Nordqvist 74.6
## 12 12 A Lim Kim 74.4
## 13 13 Hannah Green 74.3
## 14 14 Celine Boutier 73.9
## 15 15 In Gee Chun 73.6
## 16 16 Lilia Vu 73.5
## 17 17 Emily Pedersen 73.5
## 18 18 Sei Young Kim 73.5
## 19 19 Jennifer Kupcho 73.4
## 20 20 Daniela Darquea 73.3
## 21 21 Matilda Castren 73.1
## 22 22 Lauren Coughlin 73.1
## 23 23 Peiyun Chien 73.1
## 24 24 Charley Hull 73.0
## 25 25 Andrea Lee 72.9
## 26 26 Lydia Ko 72.9
## 27 27 Allisen Corpuz 72.8
## 28 28 Nasa Hataoka 72.6
## 29 29 Pajaree Anannarukarn 72.6
## 30 30 Jeong Eun Lee 72.6
## 31 31 Sarah Schmelzel 72.5
## 32 32 Chella Choi 72.5
## 33 33 Hyo Joo Kim 72.4
## 34 34 Ayaka Furue 72.4
## 35 35 Amy Yang 72.4
## 36 36 Marina Alex 72.3
## 37 37 Jessica Korda 72.1
## 38 38 Lindy Duncan 72.0
## 39 39 Danielle Kang 71.9
## 40 40 Wei-Ling Hsu 71.8
## 41 41 Jin Young Ko 71.5
## 42 42 Carlota Ciganda 71.5
## 43 43 Perrine Delacour 71.3
## 44 44 Ryann O'Toole 70.8
## 45 45 Yealimi Noh 70.8
## 46 46 Lizette Salas 70.8
## 47 47 Moriya Jutanugarn 70.7
## 48 48 Albane Valenzuela 70.7
## 49 49 Alison Lee 70.6
## 50 50t Caroline Masson 70.6
## 51 50t Lauren Stephenson 70.6
## 52 52 Elizabeth Szokol 70.6
## 53 53 Ariya Jutanugarn 70.5
## 54 54 Leona Maguire 70.4
## 55 55t Cheyenne Knight 70.4
## 56 55t Gaby Lopez 70.4
## 57 55t Sophia Schubert 70.4
## 58 58 Nanna Koerstz Madsen 70.3
## 59 59 Casey Danielson 70.2
## 60 60 Madelene Sagstrom 70.1
## 61 61 Jenny Shin 70.1
## 62 62t Gina Kim 70.1
## 63 62t Alena Sharp 70.1
## 64 64 Dewi Weber 70.1
## 65 65 So Yeon Ryu 70.0
## 66 66 Haylee Harford 70.0
## 67 67 Na Rin An 69.9
## 68 68 Pornanong Phatlum 69.8
## 69 69 Brittany Altomare 69.8
## 70 70 Kelly Tan 69.7
## 71 71 Sarah Kemp 69.6
## 72 72 Hinako Shibuno 69.4
## 73 73 Stephanie Kyriacou 69.4
## 74 74 Ruixin Liu 69.4
## 75 75 Caroline Inglis 69.2
## 76 76 Ruoning Yin 69.1
## 77 77 Mina Harigae 69.1
## 78 78 Inbee Park 69.0
## 79 79 Mi Hyang Lee 69.0
## 80 80 Annie Park 68.9
## 81 81 Jennifer Chang 68.9
## 82 82 Stacy Lewis 68.9
## 83 83 Esther Henseleit 68.7
## 84 84 Georgia Hall 68.7
## 85 85 Ashleigh Buhai 68.6
## 86 86 Paula Reto 68.6
## 87 87 Yuka Saso 68.6
## 88 88 Patty Tavatanakit 68.6
## 89 89 Yu Liu 68.6
## 90 90 Maude-Aimee Leblanc 68.5
## 91 91 Min Lee 68.4
## 92 92t Jasmine Suwannapura 68.4
## 93 92t Emma Talley 68.4
## 94 94 Cydney Clanton 68.3
## 95 95 Wichanee Meechai 68.3
## 96 96 Jaye Marie Green 68.2
## 97 97 Amy Olson 68.2
## 98 98 Eun-Hee Ji 68.2
## 99 99 Giulia Molinaro 68.2
## 100 100 Jenny Coleman 68.1
## 101 101 Maria Fassi 68.0
## 102 102 Lindsey Weaver 67.9
## 103 103 Morgane Metraux 67.9
## 104 104 Bronte Law 67.9
## 105 106 Sung Hyun Park 67.9
## 106 107 Pernilla Lindberg 67.8
## 107 108 Pauline Roussin-Bouchard 67.8
## 108 109 Celine Herbin 67.6
## 109 110 Frida Kinhult 67.6
## 110 111 Isi Gabsa 67.6
## 111 112 Haeji Kang 67.6
## 112 113 Brittany Lincicome 67.5
## 113 114 Weiwei Zhang 67.4
## 114 115 Stephanie Meadow 67.2
## 115 116 Dana Finkelstein 67.1
## 116 117 Gemma Dryburgh 67.1
## 117 118 Robynn Ree 67.0
## 118 119 Gerina Mendoza 66.7
## 119 120 Jennifer Song 66.6
## 120 121 Na Yeon Choi 66.1
## 121 122 Bianca Pagdanganan 66.0
## 122 123 Janie Jackson 66.0
## 123 124 Amanda Doherty 65.6
## 124 125 Sanna Nuutinen 65.6
## 125 126 Karis Davidson 65.5
## 126 127 Alana Uriell 65.3
## 127 128 Lauren Hartlage 65.1
## 128 129 Muni He 65.1
## 129 130 Mariah Stackhouse 65.0
## 130 131 Vivian Hou 65.0
## 131 132 Angel Yin 65.0
## 132 133 Agathe Laisne 64.9
## 133 134 Charlotte Thomas 64.8
## 134 135 Rachel Rohanna 64.8
## 135 136 Sophia Popov 64.7
## 136 137 Ana Belac 64.7
## 137 138 Kaitlyn Papp 64.6
## 138 139 Christina Kim 64.3
## 139 140 Mel Reid 64.3
## 140 141 Brittany Lang 64.1
## 141 142 Linnea Johansson 64.0
## 142 143 Elizabeth Nagel 64.0
## 143 144 Fatima Fernandez Cano 63.5
## 144 145 Su-Hyun Oh 63.5
## 145 146 Mirim Lee 63.5
## 146 147 Cristie Kerr 63.4
## 147 148 Marissa Steen 63.3
## 148 149 Tiffany Chan 63.3
## 149 150 Katherine Perry-Hamski 63.0
## 150 151 Aditi Ashok 63.0
## 151 152 In-Kyung Kim 62.8
## 152 153 Yu-Sang Hou 62.7
## 153 154 Brianna Do 62.5
## 154 155 Maddie Szeryk 62.4
## 155 156 Katherine Kirk 62.3
## 156 157 Angela Stanford 61.5
## 157 158 Brooke Matthews 60.8
## 158 159 Savannah Vilaubi 60.6
## 159 160 Allison Emrey 59.7
## 160 161 Lauren Kim 58.6
## 161 162 Yae Eun Hong 58.5
## 162 163 Sarah Jane Smith 57.0
##
## [[4]]
## rank name rounds score_average_actual
## 1 1 Lydia Ko 85 68.988
## 2 2 Hyo Joo Kim 59 69.390
## 3 3 Atthaya Thitikul 96 69.458
## 4 4 Brooke Henderson 76 69.513
## 5 5 Xiyu Lin 88 69.545
## 6 6 Nelly Korda 50 69.660
## 7 7 Minjee Lee 72 69.694
## 8 8 Lexi Thompson 60 69.700
## 9 9 Danielle Kang 61 69.721
## 10 10 Hyejin Choi 94 69.723
## 11 11 Hannah Green 79 69.823
## 12 12 Celine Boutier 86 69.860
## 13 13 Andrea Lee 67 69.925
## 14 14 Nasa Hataoka 95 69.937
## 15 15 Madelene Sagstrom 79 70.127
## 16 16 Charley Hull 55 70.145
## 17 17 Megan Khang 81 70.148
## 18 18 Sei Young Kim 72 70.194
## 19 19 In Gee Chun 71 70.197
## 20 20 Lilia Vu 84 70.202
## 21 21 Ayaka Furue 94 70.340
## 22 22 Georgia Hall 70 70.357
## 23 23 Jessica Korda 49 70.388
## 24 24 Amy Yang 65 70.415
## 25 25 Leona Maguire 80 70.450
## 26 26 Chella Choi 84 70.464
## 27 27 Jodi Ewart Shadoff 81 70.506
## 28 28 A Lim Kim 101 70.535
## 29 29 Carlota Ciganda 76 70.579
## 30 30 Jennifer Kupcho 86 70.593
## 31 31 Alison Lee 86 70.616
## 32 32 Jin Young Ko 55 70.673
## 33 33 Cheyenne Knight 78 70.692
## 34 34 Yuka Saso 88 70.727
## 35 35 Jeong Eun Lee 75 70.747
## 36 36 Daniela Darquea 32 70.750
## 37 37 Lizette Salas 69 70.754
## 38 38 Sarah Schmelzel 79 70.759
## 39 39 Gaby Lopez 78 70.808
## 40 40 Marina Alex 79 70.823
## 41 41 Allisen Corpuz 73 70.877
## 42 42 Nanna Koerstz Madsen 65 70.892
## 43 43 Ruoning Yin 43 70.930
## 44 44 Inbee Park 48 70.938
## 45 45 Na Rin An 85 70.976
## 46 46 Eun-Hee Ji 66 70.985
## 47 47t Ally Ewing 67 71.000
## 48 47t Anna Nordqvist 78 71.000
## 49 49 Frida Kinhult 70 71.014
## 50 50 Karis Davidson 32 71.063
## 51 51 Pajaree Anannarukarn 87 71.080
## 52 52 Ryann O'Toole 80 71.088
## 53 53 Albane Valenzuela 78 71.090
## 54 54 So Yeon Ryu 66 71.091
## 55 55 Moriya Jutanugarn 88 71.114
## 56 56 Paula Reto 82 71.122
## 57 57 Brittany Altomare 82 71.134
## 58 58 Ruixin Liu 60 71.167
## 59 59 Jenny Shin 68 71.176
## 60 60 Ashleigh Buhai 73 71.192
## 61 61 Caroline Masson 67 71.194
## 62 62 Jasmine Suwannapura 78 71.205
## 63 63 Gemma Dryburgh 82 71.220
## 64 64 Wei-Ling Hsu 72 71.236
## 65 65 Stephanie Kyriacou 66 71.242
## 66 66 Alena Sharp 31 71.258
## 67 67 Emily Pedersen 73 71.301
## 68 68 Stacy Lewis 73 71.315
## 69 69 Ariya Jutanugarn 85 71.341
## 70 70 Lauren Stephenson 67 71.343
## 71 71 Mina Harigae 71 71.352
## 72 72 Hinako Shibuno 71 71.366
## 73 73 Lindy Duncan 26 71.385
## 74 74t Jennifer Chang 60 71.400
## 75 74t Perrine Delacour 50 71.400
## 76 76 Pornanong Phatlum 88 71.455
## 77 77 Amanda Doherty 60 71.467
## 78 78 Matilda Castren 76 71.474
## 79 79 Emma Talley 78 71.474
## 80 80 Pauline Roussin-Bouchard 71 71.479
## 81 81 Yu Liu 73 71.507
## 82 82 Lauren Coughlin 65 71.508
## 83 83 Caroline Inglis 46 71.543
## 84 84 Stephanie Meadow 76 71.592
## 85 85 Haeji Kang 62 71.613
## 86 86 Yealimi Noh 79 71.646
## 87 88 Sarah Kemp 63 71.651
## 88 89 Wichanee Meechai 88 71.682
## 89 90 Kelly Tan 74 71.743
## 90 91 Patty Tavatanakit 64 71.750
## 91 92 Lindsey Weaver 65 71.754
## 92 93 Dana Finkelstein 54 71.759
## 93 94 Peiyun Chien 60 71.783
## 94 95 Esther Henseleit 69 71.812
## 95 96 Elizabeth Szokol 30 71.833
## 96 97 Angel Yin 72 71.861
## 97 98 Isi Gabsa 59 71.881
## 98 99 Min Lee 60 71.883
## 99 100 Brittany Lang 39 71.923
## 100 101 Maria Fassi 55 71.927
## 101 102 Mi Hyang Lee 46 71.935
## 102 103 Brittany Lincicome 32 71.938
## 103 104 Pernilla Lindberg 55 71.945
## 104 105 Charlotte Thomas 59 71.949
## 105 106 Sophia Schubert 72 71.986
## 106 107t Aditi Ashok 72 72.000
## 107 107t Morgane Metraux 61 72.000
## 108 107t Dewi Weber 54 72.000
## 109 110 Bronte Law 57 72.035
## 110 111 Gina Kim 31 72.065
## 111 112 Amy Olson 58 72.086
## 112 113 Annie Park 64 72.125
## 113 114 Kaitlyn Papp 48 72.146
## 114 115 Maude-Aimee Leblanc 65 72.215
## 115 116 Jennifer Song 64 72.219
## 116 117 Haylee Harford 42 72.238
## 117 118 Alana Uriell 53 72.264
## 118 119 Sung Hyun Park 55 72.273
## 119 120 Gerina Mendoza 47 72.277
## 120 121 Su-Hyun Oh 60 72.283
## 121 122 Celine Herbin 29 72.345
## 122 123 Cristie Kerr 29 72.379
## 123 124 Linnea Johansson 55 72.382
## 124 125 Tiffany Chan 31 72.419
## 125 126 Yae Eun Hong 54 72.463
## 126 127 Giulia Molinaro 56 72.464
## 127 128 Jaye Marie Green 36 72.472
## 128 129 Bianca Pagdanganan 48 72.521
## 129 130 Muni He 49 72.531
## 130 131 Robynn Ree 38 72.553
## 131 132 Maddie Szeryk 34 72.559
## 132 133 Ana Belac 50 72.620
## 133 134 Katherine Kirk 24 72.708
## 134 135 Weiwei Zhang 22 72.727
## 135 136 Mariah Stackhouse 20 72.750
## 136 137t Katherine Perry-Hamski 47 72.809
## 137 137t Rachel Rohanna 47 72.809
## 138 139 In-Kyung Kim 40 72.850
## 139 140 Cydney Clanton 50 72.880
## 140 141 Sarah Jane Smith 27 72.889
## 141 142 Brooke Matthews 34 72.912
## 142 143 Janie Jackson 55 72.927
## 143 144 Lauren Hartlage 40 72.950
## 144 145t Na Yeon Choi 42 72.952
## 145 145t Sophia Popov 42 72.952
## 146 147t Casey Danielson 39 73.000
## 147 147t Yu-Sang Hou 28 73.000
## 148 147t Christina Kim 45 73.000
## 149 147t Agathe Laisne 41 73.000
## 150 151 Allison Emrey 52 73.019
## 151 152 Sanna Nuutinen 47 73.043
## 152 153 Mel Reid 47 73.128
## 153 154 Jenny Coleman 61 73.131
## 154 155 Angela Stanford 42 73.143
## 155 156 Brianna Do 28 73.464
## 156 157 Marissa Steen 25 73.840
## 157 158 Elizabeth Nagel 25 73.920
## 158 159 Vivian Hou 23 74.087
## 159 160 Savannah Vilaubi 30 74.133
## 160 161 Fatima Fernandez Cano 32 74.188
## 161 162 Lauren Kim 18 74.333
## 162 163 Mirim Lee 26 74.462All done!! And just like that, we’ve downloaded four different web pages, extracted the tabled info, and formatted them without copying and pasting any code. The same process for all four was only used one time to write the initial function. Just apply some final formatting to clean it up a bit and combine the separate data frames into a single, unified one.
lpga_data= lpga_data %>%
reduce(left_join, by="name") %>% # Combine all list levels into a single tibble, matching by the "Name" column
select(-contains("rank.")) |>
rename("score_average"="score_average_actual")
# VOILA!
head(lpga_data)## name distance putt_average greens_hit rounds score_average
## 1 Maria Fassi 279.255 1.834 68.0 55 71.927
## 2 Bianca Pagdanganan 277.052 1.844 66.0 48 72.521
## 3 Yuka Saso 275.614 1.752 68.6 88 70.727
## 4 Brooke Matthews 275.279 1.868 60.8 34 72.912
## 5 A Lim Kim 274.741 1.794 74.4 101 70.535
## 6 Emily Pedersen 274.669 1.845 73.5 73 71.30110.3.2 Non-reproducible example (Juvenile Life Without Parole study)
In the Juvenile Lifers study, there were a series of questions that participants rated on a scale of 0-100 in terms of difficulty. Part of our analysis involved taking the ratings on those variables and giving them relative rankings, so that each of the 6 variables in the series was rated from the least to most difficult, by participant.
Now if we only needed to compute these rankings once this wouldn’t have been any big deal; however, we needed to do it three times.
Much of the same code and the same process would need to be copied and pasted, resulting in a very long, messy, harder to read script. With purrr however, we can reduce the redundancies to a minimum, saving time and reducing the chances of mistakes.
Step 1. Just like before, the first step is to find a line-by-line solution for a single item, and then to generalize this into a shortcut function that can be applied to the any item “i” in a series of items.
For the sake of brevity, I’m going to skip most of that and just include the functions below.
load("C:/Github Repos/Studies/JLWOP/Data and Models/jlwop_reentry_survey.RData")
#### CREATE THE DATA SETS WE NEED####
na_blank=jlwop_reentry_survey # analysis 1 keeps the data as-is
na_zero=jlwop_reentry_survey %>% # supplementary analysis replaces the NA's with 0
mutate(across(c(barrier_housing:barrier_identification), replace_na,0))
rm(jlwop_reentry_survey) # remove old data set to avoid confusion
#### Functions ####
# transformation function to wrangle the data into proper formatting
rotate_data=function(data, variable_prefix){
data=data %>%
pivot_longer(
cols= starts_with(variable_prefix), # collect all the desired variables (i.e., columns)....
names_to = "variable", #...and put them into a new categorical variable called "variable"
values_to = "participant_score") %>% # ...and store their values in a new variable called "participant_score"
arrange(unique,participant_score) %>%
select(c(unique, participant_score, variable)) %>% # keep only these 3 variables
relocate(variable, .before = participant_score) # put the newly created variable up front
return(data)
}
# creating the rankings for each variable; then transform data back to original structure
rank_and_unpivot=function(data){
data=data %>%
group_by(unique) %>% # group the scores so they can be ranked by participant
mutate(rank1=dense_rank(participant_score), # create ranking variable
rank=max(rank1,na.rm = TRUE) + 1 - rank1) %>% # fix ranks by flipping to ascending order
mutate(rank=factor(rank)) %>% # convert rank to factor structure
select(-rank1)
# Pivot back to wide
data=data %>%
pivot_wider(names_from = variable, values_from = rank:participant_score) %>%
ungroup() # un-group the data and delete the generated names
return(data)
}Step 2. Again, like before, we want to combine all elements of interest into some object. Once we have that, we then pass said object to map() and supply the map call with our custom function.
dfs=list(na_blank=na_blank, na_zero=na_zero) %>% # create lists
map(.f=rotate_data, variable_prefix = "barrier") %>% # apply custom function along whole list
map(rank_and_unpivot) # again!! DO IT AGAIN! With another function this time.
# extract list elements to make them data frames again
list2env(dfs, globalenv())
rm(dfs) #discard list. It has fulfilled its purpose.And just like that, we’re done!
10.3.3 Example 3: Read/Import several files at once with map()
Multiple ways you can do this….
################### Option 1: read all into the global environment, keeping them as SEPERATE df's ###############
legaldmlab::read_all(path="Data Repository/Stats Data Repository/JASP files", extension = ".csv")
# Option 1.A: Squish ALL OBJECTS in the working environment into a list
# Again, note the "ALL OBJECTS" part; make sure there are no functions or other things in the environment when you run this.
files=mget(ls())
############# Option 2: Read in all files as a LIST of df's, then stitch in the names #####################################
files=paste0(here::here("Data Repository", "Stats Data Repository", "JASP files", "/"),
list.files(path=here::here("Data Repository", "Stats Data Repository", "JASP files"), pattern = ".csv"))
files_list=files |>
map(readr::read_csv)
names(files_list)=file.path(here::here("Data Repository", "Stats Data Repository", "JASP files")) |> #specify file path as a string
list.files(pattern = ".csv") |> # pass the path string to list files; search in this location for files with this extension
gsub(pattern=".csv", replacement = "") # remove this pattern to save only the name
# Option 2.A: Extract each data frame and put everything into the global environment
list2env(cog_data, globalenv())10.4 Other purrr commands
Note that map() always returns a list, and depending on the output that you want, you may need to use a variation of map(). These variations are as follows:
| Command | Return |
|---|---|
map_lgl() |
logical vector |
map_int() |
integer vector |
map_dbl() |
double vector |
map_chr() |
character vector |
walk() |
only returns the side effects of a function |
10.4.1 walk and walk2
Walk() is useful for when you just want to plot something or write a save file to your disk, etc. It does not give you any return to store something in the environment. You use it to write/read files, open graphics windows, and so on.
Example: Writing multiple files at once
Utilize purrr::walk2() to apply a function iteratively on TWO objects simultaneously. To save multiple .csv files with walk2, we need two distinct lists: 1. A list of data frames that we wish to export, 2. and the file paths, complete with the file names and extensions, for each file to be written.
First create and define both list items. Then apply walk2() to pluck an element from list 1 and its corresponding element from list 2, and apply the write_csv function in for-loop fashion.
# DEMO 1: Writing multiple plots at once
# Create list one, the list of objects
figs = list(scatter_plot=scatter_plot,
multi_plot=multi_plot)
# create list 2, the list of file names
fig_names = figs |>
names() |>
map(paste0, ".png")
# pass both to purrr to use ggsave iteratively over both lists once and save all graphs with one command
walk2(figs, fig_names, ~ggsave(plot = figs,
filename = fig_names
path=here::here("Figures and Tables"),
device = "png", dpi = 300))A second demo, this time using write.csv to save/export multiple CSV files at once
# DEMO 2: Wrinting multiple .csv files at once
### Custom function ####
# Create needed function that grabs file names and stitches them together with the correct path and extension
# Included in legaldmlab package
bundle_paths=function(df_list, output_location, file_type){
names=names(df_list)
paths=rep(here::here(output_location), length(names))
extension=rep(c(file_type), length(names))
fixed_names=paste0("/",names)
path_bundle=list(paths,fixed_names, extension) %>%
pmap(., paste0)
return(path_bundle)
}
#### Exporting the .csv files for SPSS/JASP/etc. ####
# Define list 1
dfs=list(na_blank=na_blank,
na_zero=na_zero,
na_zero_helpreint=na_zero_helpreint)
# list 2
paths_csv=bundle_paths(df_list = dfs, folder_location = "JLWOP/Data and Models", file_type = ".sav")
# Iterate over all elements in list 1 and corresponding element in list 2;
# and apply the the write_csv function to each
walk2(.x=dfs, .y= paths, .f=haven::write_sav)
#### .RData file for R users ####
# Combine multiple data frames into a single .RData file and export
save(list = c("na_blank", "na_zero", "na_zero_helpreint"),
file = here::here("JLWOP", "Data and Models","ranking_data.RData"))10.4.2 map2
knitr::include_graphics(here::here("pics", "map2_a.png"))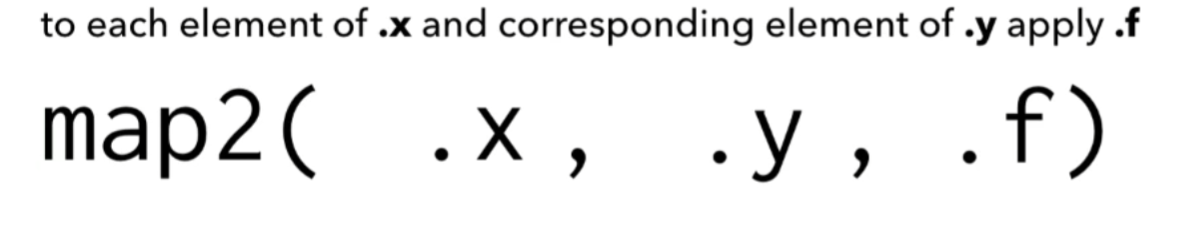
knitr::include_graphics(here::here("pics", "map2_b.png"))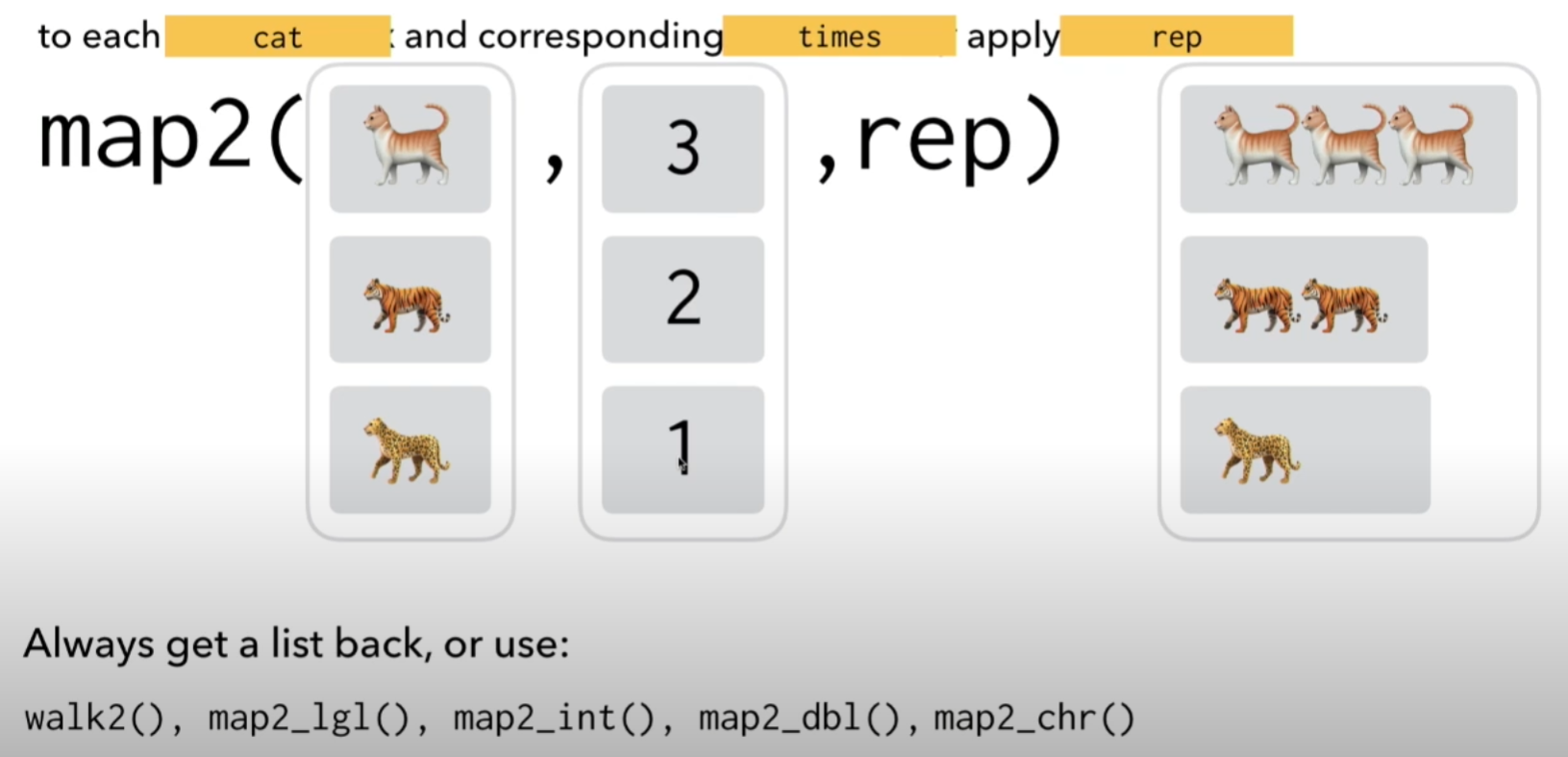
10.4.3 pmap for when you have a bunch of shit
This function is for iterating over three or more elements. As soon as you have >2 items you have to iterate over, you need pmap(), which acts on a list object called .i instead of a list object.
The list .i is a list of all the objects you want to iterate over. If you give it a list of 18 items, it iterates over all 18. If the list only has two things, it only acts on those two.
She says its easiest to imagine the list as a data frame, and the columns of the data frame like the elements of that list.
knitr::include_graphics(here::here("pics", "pmap.png"))
knitr::include_graphics(here::here("pics", "pmap_2.png"))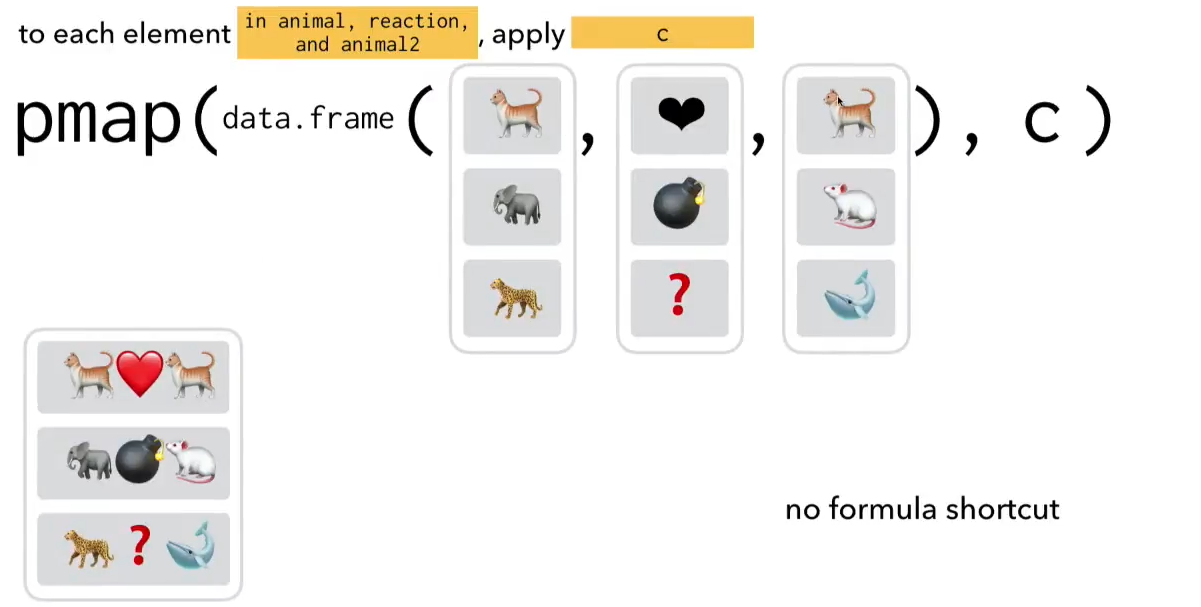
10.5 Using purrr to manage many models
Below is the full script I copied from Hadley Wickham’s lecture, which you can watch here
pacman::p_load(dplyr,purrr,tidyverse,gapminder)
#### Workflow for managing many models in R ####
# 1. Nest data with {tidyr}
# 2. Use {purrr} to map a modeling function
# 3. Use {broom} to inspect your tidy data
gapminder=gapminder %>%
mutate(year1950= year-1950) #the number of years it's been since 1950
#--------------------------------------------------------------------------------------------
#### Step 1. Nest the data. ####
# A nested data frame has one column per country. You're essentially
# creating a Russian doll; a data frame inside of a larger data frame.
by_country=gapminder %>%
group_by(continent,country) %>% # variables to keep at the top level
nest() # smush everything else into a df, and store this mini-df in its own column
# with this, you can have an entire table per row; a whole data frame for each country
# Essentially condensing a list into a table
by_country$data[[1]]
#--------------------------------------------------------------------------------------------
#### Step 2. Use purrr to map stuff. ####
# 12:50
country_model=function(df){
lm(lifeExp ~ year1950, data = df)
}
models= by_country %>%
mutate(
mod=map(data,country_model)
)
gapminder %>%
group_by(continent,country) %>%
nest() %>%
mutate(
mod= data %>% map(country_model)
)
# 27:11
#--------------------------------------------------------------------------------------------
##### Step 3. ####
# This creates another nested df inside of your main data frame that has the summary stats of each model
models=models %>% mutate(
tidy=map(mod, broom::tidy), # tidy() gives model estimates
glance=map(mod,broom::glance), # glance() gives model summaries
augment=map(mod,broom::augment) # model coefficients
)
# What can you do with this nest of data frames?
# The reverse of step 1; un-nest it to unpack everything!
# 34:40
# Keeps a massive list of related information neatly organized!
unnest(models,data) # back to where we started
unnest(models,glance, .drop = TRUE)
unnest(models,tidy) …and here is a version I made of the above to manage many Latent Growth Curve models.
# CONDENSED MASTER TABLE VERSION -----------------------------------------------------------------------------
# Models table that has all models condensed
models_noCovs=tibble(
#### Define model names ####
model_name=c("Linear", "Quadratic", "Latent_Basis"),
##### List model specifications for lavaan ####
model_spec=list(
linear_model= '
# intercept and slope with fixed coefficients
i =~ 1*panss_total_400 + 1*panss_total_1000 + 1*panss_total_1600 + 1*panss_total_2200 + 1*panss_total_2800 + 1*panss_total_3400 + 1*panss_total_5200
s =~ 0*panss_total_400 + 3*panss_total_1000 + 6*panss_total_1600 + 9*panss_total_2200 + 12*panss_total_2800 + 15*panss_total_3400 + 24*panss_total_5200
',
quadratic_model= '
# intercept and slope with fixed coefficients
i =~ 1*panss_total_400 + 1*panss_total_1000 + 1*panss_total_1600 + 1*panss_total_2200 + 1*panss_total_2800 + 1*panss_total_3400
s =~ 0*panss_total_400 + 3*panss_total_1000 + 6*panss_total_1600 + 9*panss_total_2200 + 12*panss_total_2800 + 15*panss_total_3400 + 24*panss_total_5200
qs =~ 0*panss_total_400 + 9*panss_total_1000 + 36*panss_total_1600 + 81*panss_total_2200 + 144*panss_total_2800 + 225*panss_total_3400 + 576*panss_total_5200
',
latentBasis_model= '
# intercept and slope with fixed coefficients
i =~ 1*panss_total_400 + 1*panss_total_1000 + 1*panss_total_1600 + 1*panss_total_2200 + 1*panss_total_2800 + 1*panss_total_3400 + 1*panss_total_5200
s =~ 0*panss_total_400 + NA*panss_total_1000 + NA*panss_total_1600 + NA*panss_total_2200 + NA*panss_total_2800 + NA*panss_total_3400 + 1*panss_total_5200
'
),
#### Fit all models at once with purrr ####
fitted_model=model_spec |> map(lavaan::growth, data=panss_sem_data, missing="FIML"),
)
#### Add parameter estimates and fit stats ####
models_noCovs=models_noCovs |>
mutate(tidy_parameters=map(fitted_model, tidy, conf.int=.95), #parameter estimates
global_fit=map(fitted_model, performance::model_performance)) #global fit of models
#### Clean up stuff ####
models_noCovs$tidy_parameters=models_noCovs$tidy_parameters |>
map(select,-c(std.lv:std.nox, op)) |> # remove extra columns
map(mutate, estimate=round(estimate, digits = 2)) |> # round numbers
map(mutate, (across(c(std.error:p.value, conf.low, conf.high), round, 3)))
models_noCovs$global_fit=models_noCovs$global_fit |>
map(select, c(Chi2:p_Chi2, RMSEA:SRMR, CFI, AIC))Note how the functions inside map take on a slightly different form, but work the same.
Using this framework, you can easily drill down into any column and be sure that you’re accessing the right thing. Everything is always kept together, and always acted upon in the same way. This minimizes mistakes.
models_noCovs$tidy_parameters$latent_Basis_model